
ここではGensimを用いた形態素解析における、ベクトル変換について解説しています。
Gensimとは
「Gensim」とは「Word2Vec」を利用できるライブラリになります。
「Word2Vec」は単語の意味をベクトルで表現するツールになります。関連単語の抽出、類似度の算出ができる便利なツールです。
Gensimのインストール
Gensimを用いる前にライブラリをインストールしておく必要があります。
pipでインストールします。
$ pip install gensimGensimを用いた使用例
以下のプログラムではGensimを用いた使用例として、青空文庫の「黙々静観」を解析しているものになります。以下のプログラムでWord2Vecでモデルを作成した後に、類義語を抽出しています。
from janome.tokenizer import Tokenizer
from gensim.models import word2vec
import re
#1---ファイル読み込み
bindata = open('mokumokuseikan.txt', 'rb').read()
text = bindata.decode('shift_jis')
#2---先頭にあるヘッダとフッタを削除
text = re.split(r'\-{5,}',text)[2]
text = re.split(r'底本:', text)[0]
text = text.strip()
#3---形態素解析
t = Tokenizer()
results = []
#4---一行ずつの処理
lines = text.split("\r\n")
for line in lines:
s = line
s = s.replace('|', '')
s = re.sub(r'《.+?》', '', s)
s = re.sub(r'[#.+?]', '', s)
tokens = t.tokenize(s)
r = []
for tok in tokens:
if tok.base_form == "*":
w = tok.surface
else:
w = tok.base_form
ps = tok.part_of_speech
word_h = ps.split(',')[0]
if word_h in ['名詞', '形容詞', '動詞', '記号']:
r.append(w)
rl = (" ".join(r)).strip()
results.append(rl)
#5---書き込み先を開く
wakati_file = 'mokumokuseikan.wakati'
with open(wakati_file, 'w', encoding='utf-8') as fp:
fp.write("\n".join(results))
#6---Word2Vecでモデルを作成
data = word2vec.LineSentence(wakati_file)
model = word2vec.Word2Vec(data,
size=200, window=10, hs=1, min_count=2, sg=1)
model.save('mokumokuseikan.model')それでは解説していきます。
#1---ファイル読み込み
mokumoku_data = open('mokumokuseikan.txt', 'rb').read()
text = mokumoku_data.decode('shift_jis')
1の部分では、テキストファイルを読み込んでいます。
#2---先頭にあるヘッダとフッタを削除
text = re.split(r'\-{5,}',text)[2]
text = re.split(r'底本:', text)[0]
text = text.strip()2の部分では、テキストファイルの整形を行っています。不要なヘッダとフッタを削除しています。
#3---形態素解析
t = Tokenizer()
results = []
3の部分では、janomeを呼び出しています。その下にはfor構文で使用するリストを生成しています。
#4---一行ずつの処理
lines = text.split("\r\n")
for line in lines:
s = line
s = s.replace('|', '')
s = re.sub(r'《.+?》', '', s)
s = re.sub(r'[#.+?]', '', s)
tokens = t.tokenize(s)
r = []
for tok in tokens:
if tok.base_form == "*":
w = tok.surface
else:
w = tok.base_form
ps = tok.part_of_speech
word_h = ps.split(',')[0]
if word_h in ['名詞', '形容詞', '動詞', '記号']:
r.append(w)
rl = (" ".join(r)).strip()
results.append(rl)
4の部分では、一行ずつ処理しています。最初に分割し、その分割したものの中からルビ(re.sub(r’《.+?》’, ”, s))と入力注(re.sub(r’[#.+?]’, ”, s))を削除しています。その下(t.tokenize(s))で形態素解析を行っています。
r=[]以降の行では、活用の基本系(“*”)を用いて、「名詞」「形容詞」「動詞」「記号」意外の単語を除外しています。
#5---書き込み先を開く
wakati_file = 'mokumokuseikan.wakati'
with open(wakati_file, 'w', encoding='utf-8') as fp:
fp.write("\n".join(results))
5の部分では、4で行ったこと結果の書き込み先を指定しています。
#6---Word2Vecでモデルを作成
data = word2vec.LineSentence(wakati_file)
model = word2vec.Word2Vec(data,
size=200, window=10, hs=1, min_count=2, sg=1)
model.save('mokumokuseikan.model')最後に6の部分では、Word2Vecでモデルを作成しています。
これでモデルが完成しました。
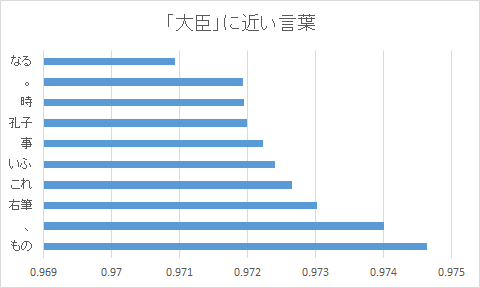
以下は、「大臣」の類義語を抽出した結果です。
from gensim.models import word2vec
model = word2vec.Word2Vec.load('kokoro.model')
model.most_similar(positive=['大臣'])
#[('もの', 0.9746307730674744),
# ('、', 0.9739990234375),
# ('右筆', 0.973025918006897),
# ('これ', 0.9726450443267822),
# ('いふ', 0.9723975658416748),
# ('事', 0.9722230434417725),
# ('孔子', 0.9719905853271484),
# ('時', 0.9719443917274475),
# ('。', 0.9719370603561401),
# ('なる', 0.9709278345108032)]結果を見ると孔子が出てくるなど何となく、政治について書かれているのかなと、分からなくもないですね。
ちなみに本文は政治に関する内容になっています。お時間ある方は読んでみて下さい「黙々静観」。
その他、Gensimを用いた使用例
| 項目 | 内容 |
| Under construction . . . | Under construction . . . |