
ここでは、Pythonにおける複数の「xlsx」ファイルの結合方法について解説しています。
事前に準備すること
プログラムを動かす前に事前に結合したいファイルのものとプログラム自身を同一フォルダに格納しておきます。以下のプログラムでは同一フォルダ内にあることが前提となっています。
詳しくはこちらを参照して下さい。
行ったこと
Amazonアソシエイトレポートを事前に数年分ダウンロードしておき、それぞれの「Fee-Earnings」というシートにある「紹介料」を抽出して結合しました。
結合プログラム
#結合プログラム
import glob
import pandas as pd
#1---フォルダ内のxlsxファイルの一覧を取得
files = sorted(glob.glob('*.xlsx'))
#2---ファイル数を取得
file_number = len(files)
#3---xlsxファイルの中身を読み出して、リスト形式にまとめる
xlsx_list = []
sheet_name = "Fee-Earnings"
for file in files:
xlsx_list.append(pd.read_excel(file,sheet_name,header=1,usecols=[11]))
#4---xlsxファイルの結合
merge_xlsx = pd.concat(xlsx_list)
#5---xlsxファイル出力
merge_xlsx.to_excel('merge.xlsx')
#6---完了合図
print(file_number,' 個のxlsxファイルを結合完了!!')
はじめに、1の部分で「glob()」モジュールを用いて、フォルダ内にある全てのxlsxファイルを取得します。「*.xlsx」とすることで全てのxlsxファイルの一覧を取得します。次に2の部分では結合するファイル数を取得しています。最後にメッセージを出力するときに使用しているだけなので、ここと6の部分は無くても問題ありません。
3の部分でxlsxファイルをリスト型で格納しています。取り出したい文字列がExcel上では、2行目、L列目ですので、headerで1、usecolsで11としています。
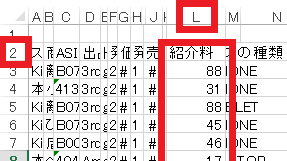
pd.read_excel(file,sheet_name,header=1,usecols=[11])読み込む上できもとなる「header」は開始行を指定するパラメータです。また「usecols」は列を指定するパラメータです。
「header」の特徴としては、指定せずに読み込むと最初の行が読み込まれてしまいます。
「usecols」はリスト型で記述するので、範囲を複数指定できます。「usecols=[6,11,13]」という感じで、必要な情報だけを簡単に取捨選択可能です。
4の部分でconcat()を用いてファイルを結合します。5の部分で「merge.xlsx」という名前で出力しています。おまけに6の部分で結合の終了合図としています。
出力結果
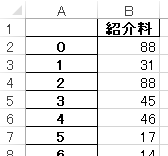
出力結果としては、数値の抽出となります。抽出する項目を増やすなどして様々なパラメータを組合せることで、高度な解析が可能となります。