
ここでは「Computational Vision at CALTECH」の画像データセットを利用した類似画像を検索する方法について解説しています。
CALTECHとは
「Computational Vision at CALTECH」とはカリフォルニア工科大学が機械学習のために配布している画像データセットです。
様々な画像のデータセットがあり、機械学習を学ぶ際の貴重なデータとなります。
行ったこと
「Computational Vision at CALTECH」のデータセットを用いて、Average Hashを算出して類似画像を探索するプログラムを作成しました。
使用したデータセットは「CALTECH256」になります。
準備すること
下記のURLからデータを保存します。
>>>Computational Vision at CALTECH
ダウンロード手順
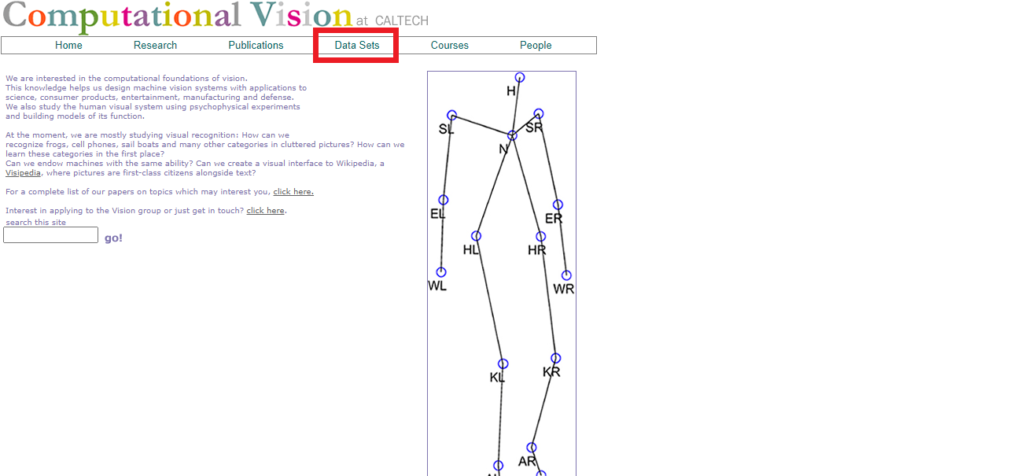
URLから飛んで、「Data Sets」を選択します。

次に「Caltech-256」を選択して「ダウンロード」します。
プログラム
from PIL import Image
import numpy as np
import os, re
#1---ファイルパスの指定
search_path = "./256_ObjectCategories"
cache_path = "./cache_csv"
#2---画像データをAverage hashに変換
def average_hash(fname, size = 16):
fname2 = fname[len(search_path):]
#3---画像をキャッシュしておく
cache_file = cache_path + "/" + fname2.replace('/', '_') + ".csv"
#4---ハッシュ作成
if not os.path.exists(cache_file):
img = Image.open(fname)
img = img.convert('L').resize((size, size), Image.ANTIALIAS)
pixels = np.array(img.getdata()).reshape((size, size))
avg = pixels.mean()
px = 1 * (pixels > avg)
np.savetxt(cache_file, px, fmt="%.0f", delimiter=",")
#5---ファイルから読み込み
else:
px = np.loadtxt(cache_file, delimiter=",")
return px
#6---ハミング距離算出
def hamming_dist(a, b):
aa = a.reshape(1, -1)
ab = b.reshape(1, -1)
dist = (aa != ab).sum()
return dist
#7---全てのディレクトリを列挙
def enum_all_files(path):
for root, dirs, files in os.walk(path):
for f in files:
fname = os.path.join(root, f)
if re.search(r'\.(jpg|jpeg|png)$', fname):
yield fname
#8---画像検索
def find_image(fname, rate):
src = average_hash(fname)
for fname in enum_all_files(search_path):
dst = average_hash(fname)
diff_r = hamming_dist(src, dst) / 256
if diff_r < rate:
yield (diff_r, fname)
#9---検索
def compare(src_jpg):
src_file = search_path + src_jpg
html = ""
sim = list(find_image(src_file, 0.20))
sim = sorted(sim, key=lambda x:x[0])
for r, f in sim:
print(r, ">", f)
#10---関数の呼び出し
compare("/043.coin/043_0003.jpg")上記は、11の部分で基準としたい画像を指定して、比較するプログラムになります。
2~6の解説についてはこちらを参照下さい。
7の部分については指定したディレクトリの内容を列挙をしています。
8の部分では7で出力した結果を基に近い値を算出しています。
9の部分では、20%までの差異の画像を出力しています。
10の部分では関数として、画像を指定しています。
結果

結果として、似た形のものを認識したものを出力した画像になります。