

最短5分で「PDFのテキスト抽出」と「画像の取り出し」を実行できるように、Pythonの代表ライブラリを用途別に整理しました。
この記事では、英語PDF→pypdf、日本語PDF→pdfminer.six、画像抽出→pypdf/PyMuPDF(拡張)の使い分けを、コピペで動くサンプル付きで解説します。
この記事の対象
英文抽出 ⇒ pypdf
英文を抽出するなら「pypdf」で可能です。pypdf は英語PDFで威力を発揮。コードがシンプルで、動作も軽量です。
外部ライブラリのためpipでインストールしておく必要があります。以下を実行して下さい。
pip install pypdfpypdf使用例
文字抽出
from pypdf import PdfReader
reader = PdfReader("arxiv_test.pdf")
for i in reader.pages:
page = i
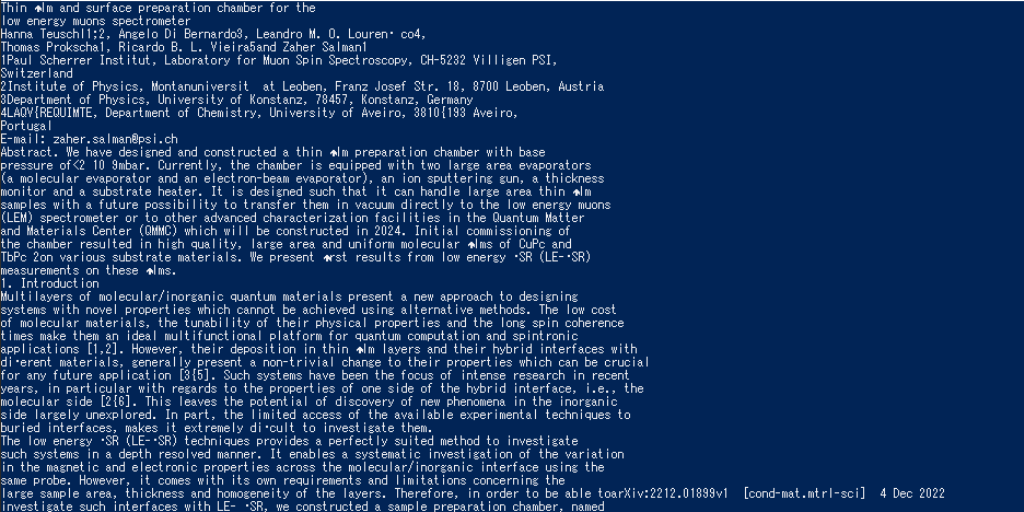
print(page.extract_text())上記のプログラムは任意のPDFファイルのすべてのページを読込んで出力しています。使用したPDFはarXivになります。使用したPDFはこちらです。
結果
指定ページだけ抽出
from pypdf import PdfReader
reader = PdfReader("arxiv_test.pdf")
page = reader.pages[0]
print(page.extract_text())上記のプログラムは任意のPDFファイルの1ページ目を読込んで出力しています。ページを指定する場合は「.pages[]」を使用することで可能です。
結果は省略します。
画像抽出
from pypdf import PdfReader
reader = PdfReader("nikon.pdf")
page = reader.pages
page_num = len(page)
count = 0
for i in range(page_num):
page = reader.pages[i]
for image_file_object in page.images:
with open(str(count) + image_file_object.name, "wb") as fp:
fp.write(image_file_object.data)
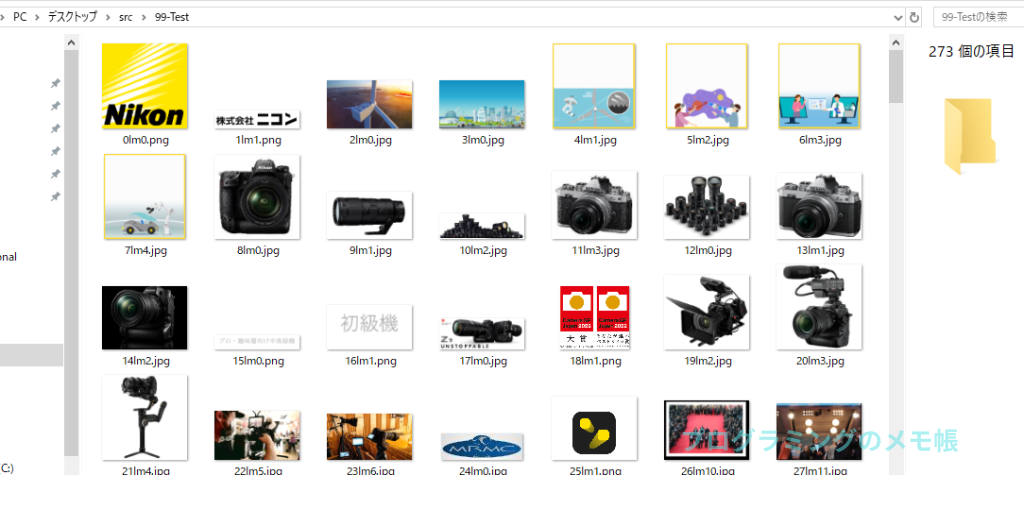
count += 1上記のプログラムは任意のPDFファイルの全てのページの画像を抽出する内容となっています。使用しているPDFファイルはNikonのIR資料になります。使用したPDFはこちらです。
結果
日本語抽出 ⇒ pdfminer.six
「pdfminer.six」は日本語の抽出ができるライブラリになります。こちらも外部ライブラリのため、以下の様にインストールしておく必要があります。
pip install pdfminer.sixpdfminer.six使用例
文字抽出
from pdfminer.high_level import extract_text
text = extract_text("nikon.pdf")
print(text)上記のプログラムは任意の日本語が含まれているPDFファイルを読み込んで出力しています。
使用しているPDFファイルはNikonのIR資料になります。使用したPDFはこちらです。
結果

指定ページだけ抽出
from pdfminer.high_level import extract_text
text = extract_text(pdf_file="nikon.pdf",page_numbers=[1])
print(text)指定ページだけを抽出した場合は引数に「page_numbers」を指定するだけです。
ポイント:extract_text はレイアウト分析も内部で行います。OCR前のスキャンPDF(文字ではなく画像のPDF)はどのライブラリでもテキスト抽出ができません。その場合は OCR(Tesseract/クラウドOCR) を併用してください。
結果は省略します。
画像抽出
PDF内の画像を抽出することも可能のようで、コマンドラインから以下を実行するだけです。
C:\hoge\hoge\python.exe C:\hoge\hoge\pdf2txt.py C:\hoge\hoge\test.pdf --output-dir C:\hoge\hoge「pythonのPath」「pdf2txt.pyのPath」「対象のPDFのPath」「–output-dir」「保存先のPath」をコマンドラインで実行するだけです。それぞれ半角スペースで区切ります。
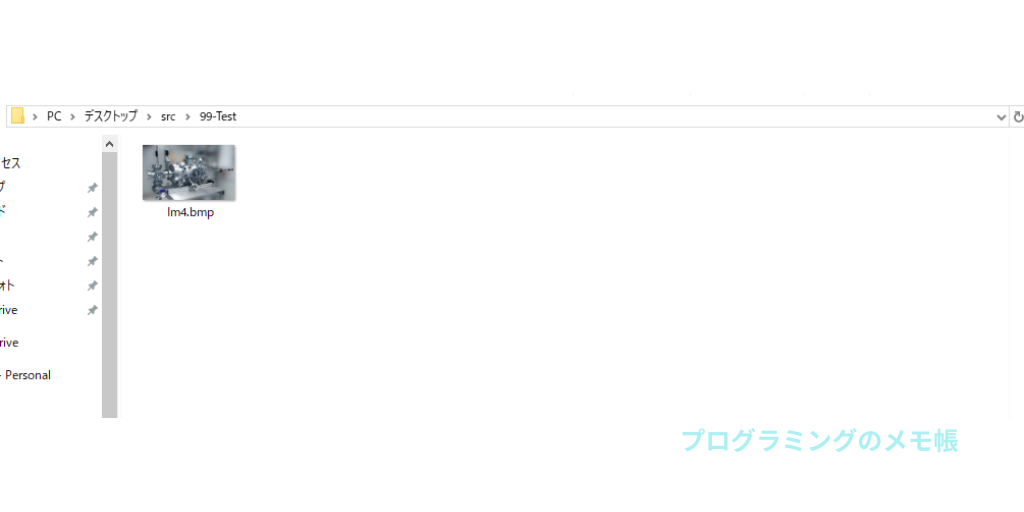
結果としては、上手く抽出できない場合が多い印象です。
結果
以下はarXivのPDFを「src」というFolderに入れて保存先を「99-Test」というFolderにして実行した結果になります。参考までに使用したPDFはこちらです。
精度/安定性を上げるなら PyMuPDF(おすすめ)
pip install pymupdfimport fitz # PyMuPDF
import os
def extract_images_pymupdf(pdf_path: str, out_dir: str = "images_mupdf"):
os.makedirs(out_dir, exist_ok=True)
doc = fitz.open(pdf_path)
seen = set() # 同一画像の重複保存回避
for pno, page in enumerate(doc, start=1):
for ino, img in enumerate(page.get_images(full=True), start=1):
xref = img[0]
if xref in seen:
continue
seen.add(xref)
pix = fitz.Pixmap(doc, xref)
try:
# ── ここが肝:PNG で保存できる色空間(RGB/GRAY)に変換 ──
if pix.colorspace and getattr(pix.colorspace, "n", 0) == 4:
# CMYK → RGB
pix = fitz.Pixmap(fitz.csRGB, pix)
elif pix.colorspace is None and pix.n > 3:
# colorspace情報が None かつ多チャンネル → とりあえず RGB へ
pix = fitz.Pixmap(fitz.csRGB, pix)
# PNG でOK(PNG は alpha も可)
out_png = os.path.join(out_dir, f"p{pno}_img{ino}.png")
pix.save(out_png)
except Exception:
# それでも失敗したら JPEG にフォールバック(αは削除)
# JPEG は alpha 非対応なので alpha を落として RGB に
pix2 = pix
if pix2.n > 3 or (pix2.colorspace and getattr(pix2.colorspace, "n", 0) != 3):
pix2 = fitz.Pixmap(fitz.csRGB, pix2)
if pix2.alpha:
pix2 = fitz.Pixmap(pix2, 0)
out_jpg = os.path.join(out_dir, f"p{pno}_img{ino}.jpg")
pix2.save(out_jpg)
finally:
pix = None
doc.close()
if __name__ == "__main__":
extract_images_pymupdf("test.pdf")PyMuPDF は画像抽出の柔軟性が高く、ページを画像化(レンダリング)したり、矩形領域を切り出すなど、実務寄りの前処理まで広く対応できます。
用途別の比較表(どれを使う?)
| 目的 | おすすめ | 理由/補足 |
|---|---|---|
| 英語PDFのテキスト抽出 | pypdf | 導入が簡単・高速。素直なPDFなら十分 |
| 日本語PDFのテキスト抽出 | pdfminer.six | 日本語の抽出に強い。レイアウト耐性が高め |
| 画像を全部取り出したい | pypdf | まずは手軽に試せる |
| 画像抽出の精度/柔軟性を上げたい | PyMuPDF | 画像レンダリングや領域抽出など拡張が強力 |
| スキャンPDF(画像だけのPDF) | OCRが必要 | Tesseract/クラウドOCRを併用 |
エラー対処・実務Tips
よくあるエラー
UnicodeEncodeError:出力先の端末がUTF-8でない。端末の文字コードをUTF-8に、またはファイル保存に切り替え。- 何も抽出されない:スキャンPDF(画像)。OCR(Tesseract、クラウドOCR)へ。
- 段組が崩れる:
pypdfでうまくいかない場合はpdfminer.sixに切り替えて比較。 - 画像が取れない:
pypdf→PyMuPDFに切替。get_images(full=True)を使う。
実務Tips
- 2ライブラリ併用:同じPDFでも抽出精度が変わるため、結果を比較して良い方を採用。
- 再現性:仮想環境(venv/poetry)+
requirements.txtでライブラリバージョン固定。 - 運用:フォルダ監視(watchdog)+ バッチ処理で自動化。

まとめ
- 英語PDF →
pypdf、日本語PDF →pdfminer.six、画像抽出 →pypdf/PyMuPDFが基本ライン - レイアウト・スキャンPDFに注意。抽出できないときはOCRを併用