

機械学習を始めたばかりで、データの正解率や損失率を可視化したいけど分からない場合がありました。
ここでは、同じようにどのようにしたら良いか分からない方に自身が躓いた点を踏まえて解説しています。
この記事の対象
準備
ここでは「scikit-learn」を使用しているので、以下でライブラリをインストールしておく必要があります。
$ pip install scikit-learnまた、学習Dataは「titanick」を用いているので、こちらも予め入手する必要があります。「kaggle」から入手します。
scikit-learnについては以下でもまとめています。ご参照下さい。
プログラム
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, log_loss
import matplotlib.pyplot as plt
#1---データの読み込み
train_df = pd.read_csv('train.csv')
#2---不要な列を削除
train_df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
#3---欠損値を補完
train_df['Age'].fillna(train_df['Age'].median(), inplace=True)
train_df['Embarked'].fillna(train_df['Embarked'].mode()[0], inplace=True)
#4---カテゴリカル変数をダミー変数に変換
train_df = pd.get_dummies(train_df)
#5---説明変数と目的変数に分割
X = train_df.drop('Survived', axis=1)
y = train_df['Survived']
#6---学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
#7---ランダムフォレストによる学習
clf = RandomForestClassifier(n_estimators=100, random_state=0)
clf.fit(X_train, y_train)
#8---テストデータによる予測
y_pred = clf.predict(X_test)
#9---正解率の計算
accuracy = accuracy_score(y_test, y_pred)
print('正解率:', accuracy)
#10---損失関数の計算
y_pred_proba = clf.predict_proba(X_test)
loss = log_loss(y_test, y_pred_proba)
print('損失関数:', loss)
#11---正解率のグラフの出力
train_accuracy = []
test_accuracy = []
test_loss = []
for i in range(1, 101):
clf = RandomForestClassifier(n_estimators=i, random_state=0)
clf.fit(X_train, y_train)
train_accuracy.append(accuracy_score(y_train, clf.predict(X_train)))
test_accuracy.append(accuracy_score(y_test, clf.predict(X_test)))
y_pred_proba = clf.predict_proba(X_test)
test_loss.append(log_loss(y_test, y_pred_proba))
plt.figure(figsize=(12, 4))
plt.subplot(121)
plt.plot(range(1, 101), train_accuracy, label='train')
plt.plot(range(1, 101), test_accuracy, label='test')
plt.xlabel('n_estimators')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(122)
plt.plot(range(1, 101), test_loss)
plt.xlabel('n_estimators')
plt.ylabel('Loss')
plt.show()
上記のプログラムは、ランダムフォレストによる生存者の予測モデルを学習して、正解率と損失関数の変化をグラフに出力するものです。
以下は解説になります。
#1---データの読み込み
train_df = pd.read_csv('train.csv')1の部分では指定のDataを読み込んでいます。
#2---不要な列を削除
train_df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)2の部分では指定の列を削除しています。
#3---欠損値を補完
train_df['Age'].fillna(train_df['Age'].median(), inplace=True)
train_df['Embarked'].fillna(train_df['Embarked'].mode()[0], inplace=True)3の部分では欠損値を補完しています。Age列の欠損値を中央値で補完し、Embarked列の欠損値を最頻値で補完しています。
詳しい説明は以下をご参照下さい。
#5---説明変数と目的変数に分割
X = train_df.drop('Survived', axis=1)
y = train_df['Survived']5の部分ではSurvived列を目的変数、それ以外の列を説明変数に分割しています。
#6---学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)6の部分ではtrain_test_split関数を使用して、データを学習用とテスト用に分割しています。
#7---ランダムフォレストによる学習
clf = RandomForestClassifier(n_estimators=100, random_state=0)
clf.fit(X_train, y_train)7の部分ではRandomForestClassifierを使用して、学習データからランダムフォレストによるモデルを学習しています。
#8---テストデータによる予測
y_pred = clf.predict(X_test)
#9---正解率の計算
accuracy = accuracy_score(y_test, y_pred)
print('正解率:', accuracy)8の部分では学習したモデルを使用して、テストデータに対して生存者予測を行っています。次に9の部分ではaccuracy_score関数で正解率を算出しています。
#10---損失関数の計算
y_pred_proba = clf.predict_proba(X_test)
loss = log_loss(y_test, y_pred_proba)
print('損失関数:', loss)10の部分ではpredict_proba関数を使用して、予測確率を計算し、log_loss関数を使用して、損失関数を算出しています。
#11---正解率のグラフの出力
train_accuracy = []
test_accuracy = []
test_loss = []
for i in range(1, 101):
clf = RandomForestClassifier(n_estimators=i, random_state=0)
clf.fit(X_train, y_train)
train_accuracy.append(accuracy_score(y_train, clf.predict(X_train)))
test_accuracy.append(accuracy_score(y_test, clf.predict(X_test)))
y_pred_proba = clf.predict_proba(X_test)
test_loss.append(log_loss(y_test, y_pred_proba))11の部分ではforループを使用して、n_estimatorsの値を1から100まで変えながら、学習を行い、trainデータとtestデータにおける正解率と損失関数を算出しています。その結果をグラフに出力しています。
【結果】
正解率: 0.8171641791044776
損失関数: 0.7693460047566363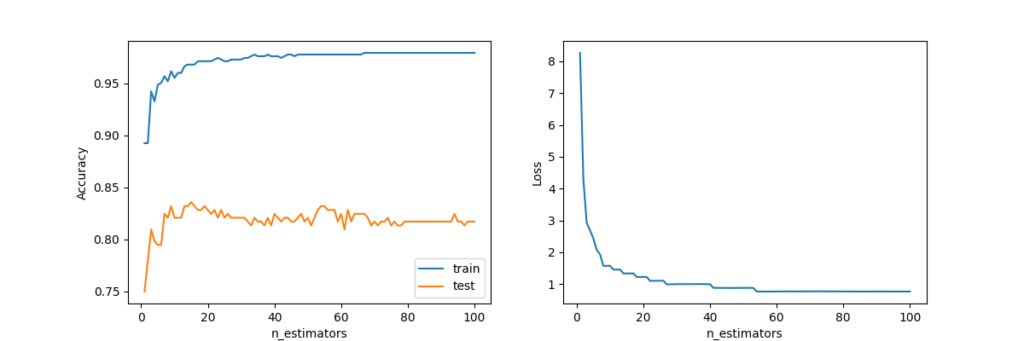
上記ではざっくりとした機械学習を紹介しました。詳細を知りたい方には「すぐに使える!業務で実践できる! PythonによるAI・機械学習・深層学習アプリのつくり方」がおすすめです。
実践形式で要所を押さえられます。
