
Pythonでデータを扱うとき、平均・分散・標準偏差は基本中の基本です。でも、
「どうやって計算するの?」
「そもそも分散って何?」
そんな疑問を持つ方も多いはず。
本記事では、NumPyを使ってこれらの基本統計量をわかりやすい実例と図解で理解できるようにお手伝いします。
この記事の対象
NumPyとは?
- High-performanceな数値計算ライブラリで、行列・配列操作に強み
- 統計計算にもよく使われ、データ分析への第一歩にはマスト
実例:平均・分散・標準偏差を計算してみよう!
import numpy as np
# データセットの作成
data = np.array([10, 20, 30, 40, 50])
print("平均:", np.mean(data))
print("分散:", np.var(data))
print("標準偏差:", np.std(data))結果&イメージ
平均: 30.0
分散: 200.0
標準偏差: 14.142135623730951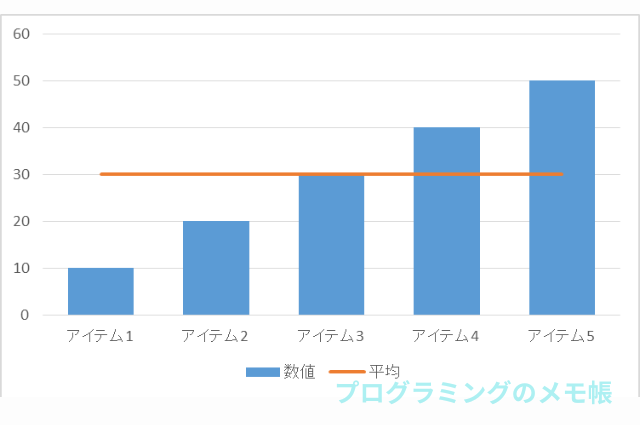
実際のデータで確認しよう
import numpy as np
data = np.array([1, 2, 2, 3, 100])
print("平均:", np.mean(data))
print("分散:", np.var(data))
print("標準偏差:", np.std(data))平均は極端な値(100)で大きく変わるけど、分散・標準偏差はデータの散らばりを示してくれる…
分散と標準偏差は、データのばらつき具合を示す統計的指標です。分散はデータポイントが平均からどれだけ離れているかを測定し、標準偏差は分散の平方根です。
結果
平均: 21.6
分散: 1537.0400000000004
標準偏差: 39.205101708833766エラーの回避ポイント
- 空配列に対して
np.mean([])を実行すると Warning+nanに。 NaNの扱いにはnp.nanmean等の代替と対処方法を紹介。
エラー例(ゼロ割りエラー)
統計計算を行う際によく発生するエラーの一つは「ゼロ割りエラー」です。分散や標準偏差を計算する際、データセットが空である場合や、分母がゼロになる場合にこのエラーが発生します。このエラーを回避するために、事前にデータの存在を確認し、適切なエラーハンドリングを行うことが重要です。
import numpy as np
# データセットの作成
data = np.array([]) # 空のデータセット
# 分散と標準偏差の計算
variance_value = np.var(data, ddof=1) # ddof=1 は不偏分散を計算するためのオプション
std_deviation_value = np.std(data, ddof=1)
if len(data) == 0:
print("データセットが空です。")
else:
print(f"分散: {variance_value}")
print(f"標準偏差: {std_deviation_value}")このコードでは、データセットが空である場合にエラーを回避し、エラーメッセージを表示します。また、ddof オプションを使用して不偏分散を計算しています。
応用例:Matplotlibで統計値を描く
import numpy as np
import matplotlib.pyplot as plt
# データセットの作成
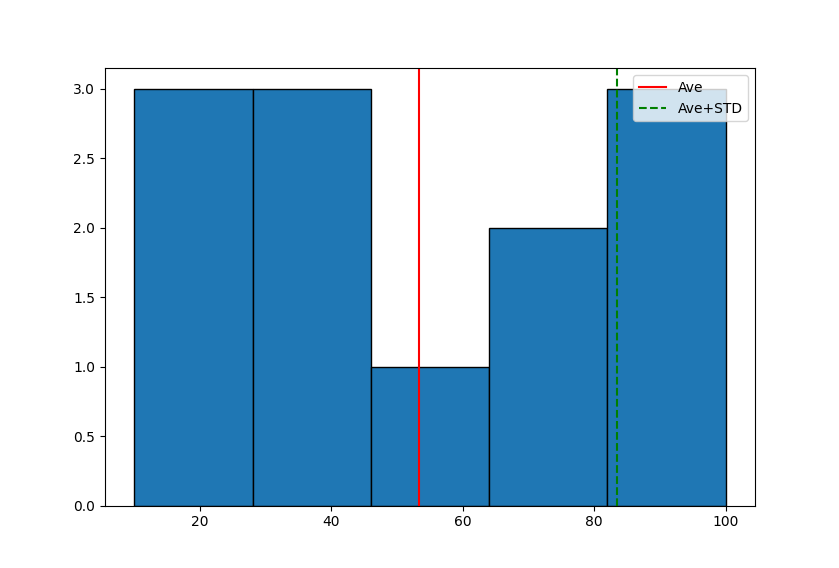
data = np.array([20, 20, 100, 40, 50, 70, 80, 90, 10, 30, 40, 90])
#描画
plt.hist(data, bins='auto',ec='black')
plt.axvline(np.mean(data), color='red', label='Ave')
plt.axvline(np.mean(data)+np.std(data), color='green', linestyle='--', label='Ave+STD')
plt.legend()
plt.show()結果
関連書籍・講座リンク
- Python 統計入門書籍:『RとPythonで学ぶ統計学入門』
関連内部リンク
まとめ
np.mean,np.var,np.stdで基本統計量は簡単に計算可能- 外れ値や空配列に注意して使おう
- 図やグラフを使えば直感的理解もアップ