

ここでは、「【Python応用】「Pandas」を用いた複数のCSVファイルの結合方法」にグラフ化までを加えた内容となっています。
行ったこと
複数のCSVファイルを結合して、そのファイルから任意のデータを基にグラフ化しました。
データの内容としては「ニコン」の株価データ10年分になります。
プログラム
import glob
import pandas as pd
import openpyxl
from openpyxl.chart import (
BarChart,
StockChart,
Reference,
Series,
)
from openpyxl.chart.axis import DateAxis, ChartLines
from openpyxl.chart.updown_bars import UpDownBars
#1---フォルダ内のCSVファイルの一覧を取得
files = sorted(glob.glob('*.csv'))
#2---ファイル数を取得
file_number = len(files)
#3---CSVファイルの中身を読み出して、リスト形式にまとめる
csv_list = []
for file in files:
csv_list.append(pd.read_csv(file,encoding='shift_jis',skiprows=[1]))
#4---CSVファイルの結合
merge_csv = pd.concat(csv_list,sort=True)
max_row = len(merge_csv) + 1
#5---columns属性の更新
merge_csv.columns = ['open','high','low','close','volume','adjustment']
#6---CSVファイル出力
merge_csv.to_excel('merge_nikon.xlsx', encoding='shift_jis')
#7---結合完了のメッセージ
print(file_number,' 個のCSVファイルを結合 ======> 結合完了')
#8---ファイルの読み出し
filename='merge_nikon.xlsx'
wb = openpyxl.load_workbook(filename)
ws = wb.active
#9---dayを追記
ws['A1'].value = 'day'
#10---High-low-closeのグラフ範囲指定
c1 = StockChart()
labels = Reference(ws, min_col=1, min_row=2, max_row=max_row)
data = Reference(ws, min_col=3, max_col=5, min_row=1, max_row=max_row)
c1.add_data(data, titles_from_data=True)
c1.set_categories(labels)
for s in c1.series:
s.graphicalProperties.line.noFill = True
#11---マーカの指定
s.marker.symbol = "dot"
s.marker.size = 5
c1.title = "High-low-close"
c1.hiLowLines = ChartLines()
#12---値のキャッシュ
from openpyxl.chart.data_source import NumData, NumVal
pts = [NumVal(idx=i) for i in range(len(data) - 1)]
cache = NumData(pt=pts)
c1.series[-1].val.numRef.numCache = cache
#13---チャート書き込みセルの指定
ws.add_chart(c1, "H5")
wb.save(filename)
プログラムは上記になります。
1~7の解説についてはこちらを参照して下さい。
それでは、8から解説していきます。
#8---ファイルの読み出し
filename='merge_nikon.xlsx'
wb = openpyxl.load_workbook(filename)
ws = wb.active
結合したファイルを読み出しています。グラフ化する際、openpyxlを用いるので、こちらでデータを読み込みます。
#9---dayを追記
ws['A1'].value = 'day'
pandasで結合したときに、A1セルの情報が欠落したので、ここで列名を書き込んでいます。
#10---High-low-closeのグラフ範囲指定
c1 = StockChart()
labels = Reference(ws, min_col=1, min_row=2, max_row=max_row)
data = Reference(ws, min_col=3, max_col=5, min_row=1, max_row=max_row)
c1.add_data(data, titles_from_data=True)
c1.set_categories(labels)
for s in c1.series:
s.graphicalProperties.line.noFill = True
最初にStockChart()メソッドを呼び出しています。次に横軸と縦軸のデータ範囲を指定しています。labelsを横軸要素、dataを縦軸要素としています。rowが行、colが列を意味しています。
add_data()メソッドに指定したデータを放り込みます。また、引数をTrueにすることで指定したデータ領域の先頭行を、グラフのラベルとして使用可能とします。
最後に繰り返し構文で線を消しています。
#11---マーカの指定
s.marker.symbol = "dot"
s.marker.size = 5
c1.title = "High-low-close"
c1.hiLowLines = ChartLines()
マーカの指定をしています。同時にグラフのタイトルを指定しています。
#12---値のキャッシュ
from openpyxl.chart.data_source import NumData, NumVal
pts = [NumVal(idx=i) for i in range(len(data) - 1)]
cache = NumData(pt=pts)
c1.series[-1].val.numRef.numCache = cache
値のキャッシュを行っています。詳しい内容はこちらを参照してください。
#13---チャート書き込みセルの指定
ws.add_chart(c1, "H5")
グラフの位置を指定しています。ここでは「H5」としています。
最後にファイルを保存して終了です。
結果
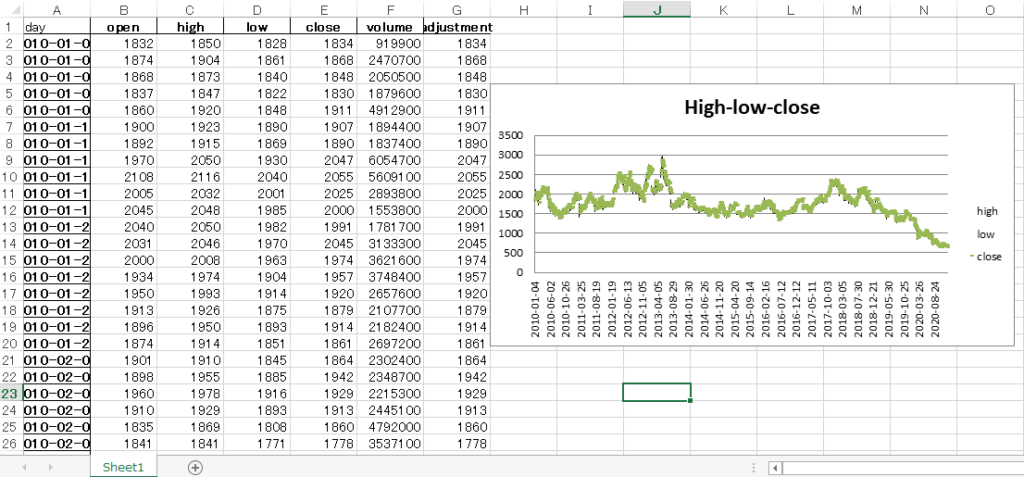
ファイルを結合してチャート作成まで自動化できました。
次の目標は解析です。
関連記事
| 項目 | 内容 |
| 「Pandas」を用いて任意のファイルから列を抽出して基礎的な統計解析する方法 | リンク先では、「【Python応用】「Pandas」を用いた複数のCSVファイルの結合からチャート化まで」を基に出力したデータを用いて基礎的な統計解析する方法について解説しています。 |