Pythonで画像内の文字抽出をする方法は、「PyOCR」というライブラリと「Tesseract」という光学式文字認識エンジンを使用するものがあります。
この記事では「PyOCR」のインストール方法と「Tesseract」のインストール方法を含めて、文字抽出する方法を紹介しています。
この記事の対象
TesseractとPyOCRのインストール
Tesseractのインストール
Windowsでは「Tesseract」のインストールはインストーラで可能です。こちらから環境に合わせてダウンロードして下さい。
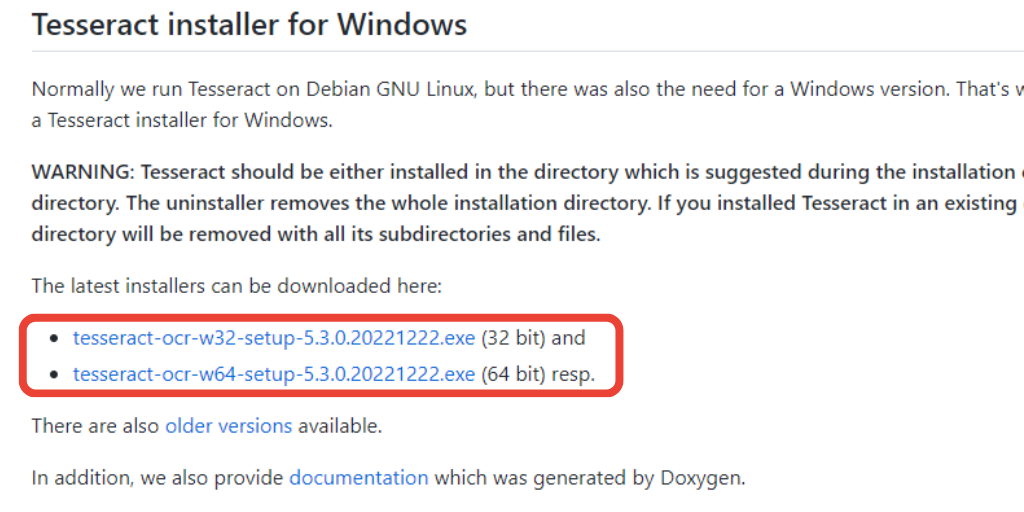
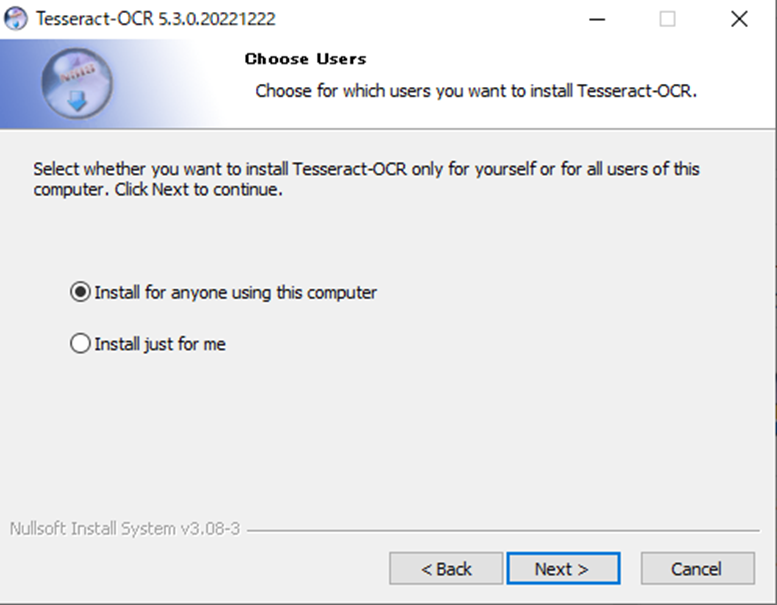
インストーラをダウンロードして、実行します。そのままデフォルトで進めます。Usersの設定では以下を行います。
次に言語のインストールを行います。
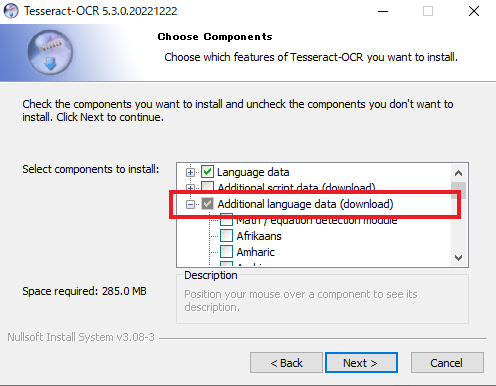
「Additional language data(download)」を選択して日本語を選択します。
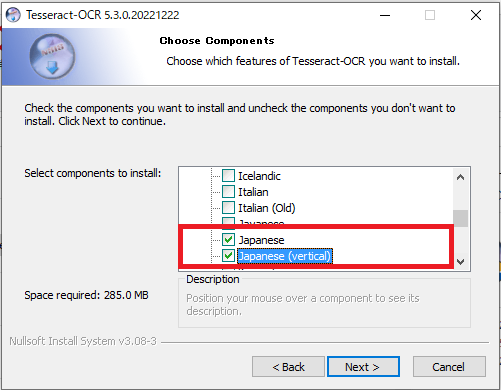
次に場所を指定します。
「Completed」になれば終了です。
PyOCRのインストール
「PyOCR」のインストールは、以下のコマンドを実行するだけです。
$ pip install pyocrプログラム
今回使用した画像は以下になります。こちらの画像から文字抽出を行っています。

from PIL import Image
import sys
import os
import pyocr
import pyocr.builders
#1---Path指定
path='C:\\Program Files\\Tesseract-OCR'
os.environ['PATH'] = os.environ['PATH'] + path
#2---OCRエンジンの取得
tools = pyocr.get_available_tools()
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
#3---文字抽出
txt = tool.image_to_string(
Image.open("icanspeak_wordcloud.png"),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print(txt)以下は解説になります。
#1---Path指定
path='C:\\Program Files\\Tesseract-OCR'
os.environ['PATH'] = os.environ['PATH'] + path1の部分ではTesseractの場所を指定しています。
#2---OCRエンジンの取得
tools = pyocr.get_available_tools()
tool = tools[0]2の部分では、OCRのエンジンを取得しています。
#3---文字抽出
txt = tool.image_to_string(
Image.open("icanspeak_wordcloud.png"),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)3の部分は、文字抽出する対象の画像と言語を指定しています。
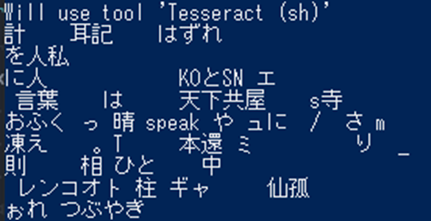
【結果】