

ここでは、青空文庫における指定した作家の掲載作品リストとurlをスクレイピングして、excelファイルに保存する方法について解説しています。
この記事の対象
行ったこと
青空文庫において、「作家別作品リスト:No.***」のナンバーを指定して掲載作品リストとurlをスクレイピングしました。
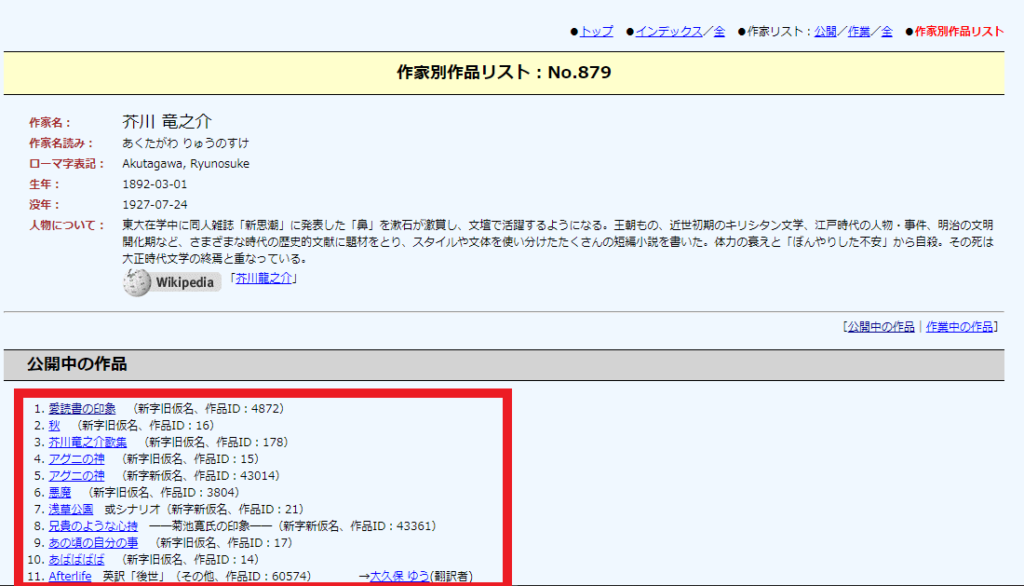
赤枠の作品リストとurlがスクレイピング内容となります。
プログラム
from bs4 import BeautifulSoup
import urllib.request as req
import openpyxl
#1---No入力
num = 879
#芥川竜之介
#2---URL指定
url = "http://www.aozora.gr.jp/index_pages/person"+str(num)+".html"
res = req.urlopen(url)
soup = BeautifulSoup(res, "html.parser")
#3---Excelファイルの作成
wb = openpyxl.Workbook()
ws = wb.active
ws['A1'].value = 'title'
ws['B1'].value = 'url'
#4---抽出
li_list = soup.select("ol>li")
i = 0
for li in li_list:
a = li.a
i += 1
if a != None:
ws.cell(row=1+int(i),column=1).value = a.string
href = a.attrs["href"]
ws.cell(row=1+int(i),column=2).value = "http://www.aozora.gr.jp" + href.replace("..","",2)
#5---ワークブックをExcelファイルとして保存
wb.save(str(num)+'.xlsx')プログラムは上記になります。numに任意の数値を指定することでスクレイピング可能です。
それでは、解説していきます。
#1---No入力
num = 879
#芥川竜之介任意の数値を指定します。ここでは、芥川竜之介にしています。
#2---URL指定
url = "http://www.aozora.gr.jp/index_pages/person"+str(num)+".html"
res = req.urlopen(url)
soup = BeautifulSoup(res, "html.parser")urlを指定して開いています。次に、開いたurl情報をBeautifulSoupに投げています。
#3---Excelファイルの作成
wb = openpyxl.Workbook()
ws = wb.active
ws['A1'].value = 'title'
ws['B1'].value = 'url'書き込むためにexcelファイルを開いています。同時にシートも作成しています。
A1とB1のセルに列名として「title」「url」を書き込んでいます。
#4---抽出
li_list = soup.select("ol>li")
i = 0
for li in li_list:
a = li.a
i += 1
if a != None:
ws.cell(row=1+int(i),column=1).value = a.string
href = a.attrs["href"]
ws.cell(row=1+int(i),column=2).value = "http://www.aozora.gr.jp" + href.replace("..","",2)スクレイピングしたい内容は「ol」要素の真下にある「li」要素の「<a>」になります。
「soup.select(“ol>li”)」は「ol」要素の直下の階層の子要素(li)を複数要素リスト型で返しています。次にfor構文でリスト型で返した分だけ処理を行っています。
作業中の作品リストも「ol>li」構造になっているので、条件指定して<a>の文字列とurlを取得します。urlに関してはフルのurlにするために「http://www.aozora.gr.jp」を加えるのと「..」という余計な文字を削除して書き込んでいます。
#5---ワークブックをExcelファイルとして保存
wb.save(str(num)+'.xlsx')最後に保存して終了です。
結果
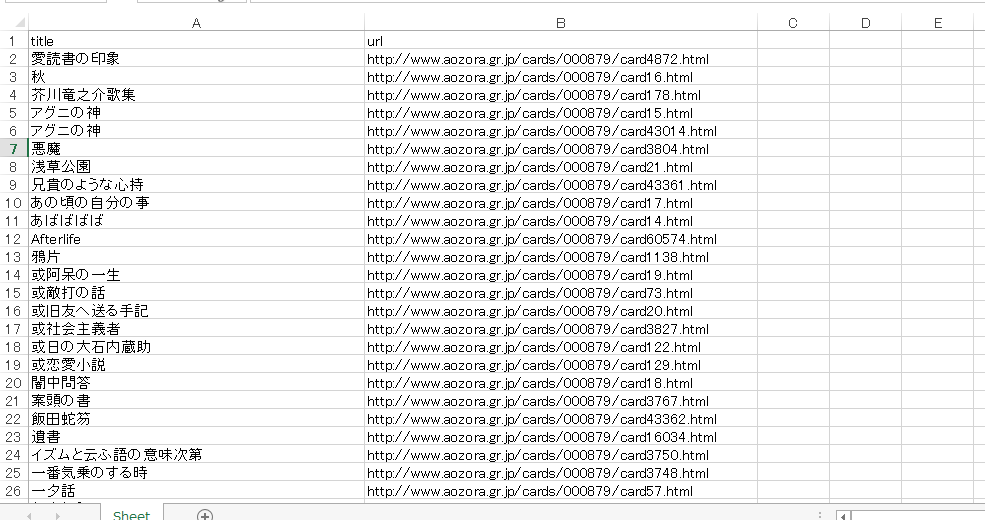
取得すると上記になります。
数値を変更して他作家の作品リストを取得してみて下さい。