

初学者にとってスクレイピングは慣れるまでプログラムを作成してから実行するまでに時間がかかります。これはサイト構造を把握することと実際に取得した情報を加工することに時間がかかるからです。
ここでは、電撃文庫における書籍情報を月別にスクレイピングする方法を基に、実践的なスクレイピング方法について解説しています。
この記事の対象
行ったこと
電撃文庫における書籍情報を月別にスクレイピングしてみました。
今回取得したい情報は以下です。
以下では2つのプログラムを紹介しています。「プログラム1」では単純なスクレイピングとExcelへの出力を行っています。
次に、「プログラム2」ではプログラム1で失敗したことを踏まえて関数化したり余計な行を削除して、無駄がないプログラムに仕上げています。
敢えて、失敗したプログラムを載せているので、何がどう変わってプログラム2になっているのか比べていただきたいです。
時間が無く、とにかく使えるプログラムだけ見たいという方は「プログラム2」をご参照下さい。
プログラム1
from bs4 import BeautifulSoup
import requests
import openpyxl
#1---調べたいデータを指定
year = 2020
month = str('01')
#2---URL指定
url = "https://dengekibunko.jp/product/"+str(year)+"/"+str(month)+"/"
#3---headers指定
headers = {"User-Agent": "*****"}
soup = BeautifulSoup(requests.get(url, headers = headers).content,'html.parser')
#4---タイトルにするセレクタ指定
title = soup.select_one("body > div > div.c-page-title.product").text
#5---エクセルを開く
wb = openpyxl.Workbook()
ws = wb.active
#6---シート名書き込み
ws.title = str(title[:4])
ws['A1'].value = 'tltle'
#7---h2の書籍タイトルの抽出
all_h2 = soup.find_all('h2')
for i in range(1,len(all_h2)):
cell_write = ws.cell(row=(i+1),column=1)
cell_write.value = all_h2[i].get_text()
#8---ワークブックをExcelファイルとして保存
wb.save(str(year)+'-'+str(month)+'.xlsx')
#9---終了の合図
print('完了')それでは解説していきます。
#1---調べたいデータを指定
year = 2020
month = str('01')
#2---URL指定
url = "https://dengekibunko.jp/product/"+str(year)+"/"+str(month)+"/"1の部分のyearとmonthで任意の値を指定して2の部分のurlに入れています。
#3---headers指定
headers = {"User-Agent": "*****"}
soup = BeautifulSoup(requests.get(url, headers = headers).content,'html.parser')3の部分では、「*****」部分に確認くんなどで自身のブラウザ情報を確認して書き込みます。その情報をBeautifulSoupに放り込んでいます。
#4---タイトルにするセレクタ指定
title = soup.select_one("body > div > div.c-page-title.product").textエクセルのシート名にする文字を抽出しています。該当箇所は以下の赤枠です。
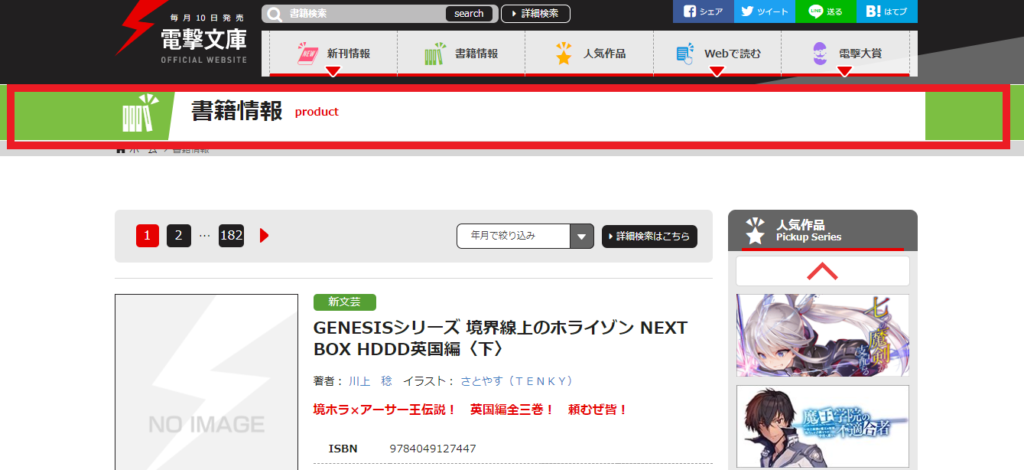
#5---エクセルを開く
wb = openpyxl.Workbook()
ws = wb.active
#6---シート名書き込み
ws.title = str(title[:4])
ws['A1'].value = 'tltle'5の部分でワークシートを呼び出しています。次に6の部分でシート名とA1セルに「title」と書き込んでいます。
#7---h2の書籍タイトルの抽出
all_h2 = soup.find_all('h2')
for i in range(1,len(all_h2)):
cell_write = ws.cell(row=(i+1),column=1)
cell_write.value = all_h2[i].get_text()7の部分ではh2の書籍タイトルを抽出しています。次に抽出した文字を1列目に書き込んでいます。抽出した箇所は以下です。
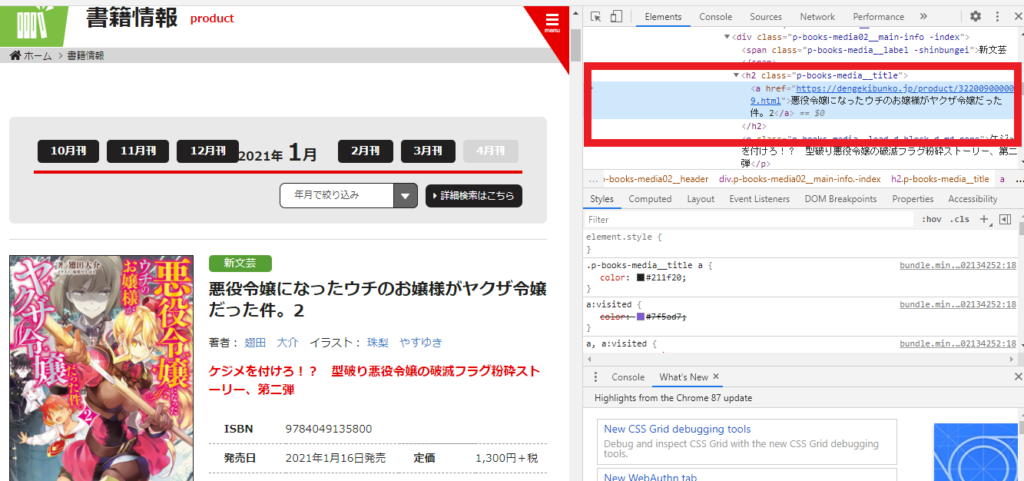
#8---ワークブックをExcelファイルとして保存
wb.save(str(year)+'-'+str(month)+'.xlsx')8の部分でエクセルを保存しています。ファイル名は年と月にしています。
#9---終了の合図
print('完了')最後に終了した合図を出力しています。
プログラム1 ⇒ 結果

スクレイピングした結果です。年と月を毎回入力してスクレイピングを行っています。このあたりは自動化できる余地がありそうです。
また、最後から2行は余計な文字列なのでこちらも排除して保存するプログラムに変更しなければならないです。
上記を踏まえてプログラムを改良したものが「プログラム2」になります。
プログラム2
from bs4 import BeautifulSoup
import requests
import openpyxl
import time
from tqdm import tqdm
def main(month,year):
#1---調べたいデータを指定
year = str(year)
if (month < 10) :
month = str("0") + str(month)
else:
month = str(month)
#2---URL指定
url = "https://dengekibunko.jp/product/"+year+"/"+month+"/"
#3---headers指定
headers = {"User-Agent": "*****"}
soup = BeautifulSoup(requests.get(url, headers = headers).content,'html.parser')
#4---タイトルにするセレクタ指定
title = soup.select_one("body > div > div.c-page-title.product").text
#5---エクセルを開く
wb = openpyxl.Workbook()
ws = wb.active
#6---シート名書き込み
ws.title = str(title[:4])
ws['A1'].value = 'title'
ws['B1'].value = 'title length'
ws['C1'].value = 'Books/Month'
#7---h2の書籍タイトルの抽出
all_h2 = soup.find_all('h2')
#8---要素数の取得
num_h2 = len(all_h2)-2
ws['C2'].value = num_h2 -1
for i in range(1,num_h2):
cell_write = ws.cell(row=(i+1),column=1)
cell_write.value = all_h2[i].get_text()
len_write = ws.cell(row=(i+1),column=2)
len_write.value = len(all_h2[i].get_text())
#9---ワークブックをExcelファイルとして保存
wb.save(year+'-'+month+'.xlsx')
time.sleep(1)
#10---main関数(データの取得)の呼び出し
for ii in tqdm(range(2015,2021)):
for jj in tqdm(range(1,13)):
main(jj,ii)プログラム1との差異は大きく3つあります。
それでは、3つの差異を中心に解説していきます。
はじめに関数化とtqdmに関連した10の部分です。
#10---main関数(データの取得)の呼び出し
for ii in tqdm(range(2015,2021)):
for jj in tqdm(range(1,13)):
main(jj,ii)関数を呼び出しているのが10の部分になります。これは取得したい年の範囲をまとめてスクレイピングするためにforで回しています。同時にtqdm(プログレスバー)で進捗状況を可視化しています。
tqdmについて知りたい方は以下をご参照下さい。
次にタイトル長の取得を行っている8の部分についてです。
#8---要素数の取得
num_h2 = len(all_h2)-2
ws['C2'].value = num_h2 -1
for i in range(1,num_h2):
cell_write = ws.cell(row=(i+1),column=1)
cell_write.value = all_h2[i].get_text()
len_write = ws.cell(row=(i+1),column=2)
len_write.value = len(all_h2[i].get_text())タイトルの長さを取得しているのは「len(all_h2[i].get_text())」です。単純にlen()関数を用いて文字数をカウントしています。そして、それをセルに書き込んでいます。
その他の解説は前述「プログラム1」をご参照下さい。
プログラム2 ⇒ 結果

結果としては目的で挙げた「タイトルの取得」「タイトル長」「1ヶ月あたりの出版数」を取得できました。
A列にタイトル、B列にタイトルの長さ、C列に出版数を出力しています。
関連記事
| 項目 | 内容 |
| 【Python応用】電撃文庫の書籍情報をスクレイピングして大雑把にまとめてみた | 「電撃文庫における月別の書籍情報のスクレイピング方法」における書籍情報の結果をまとめています。良かったら覗いてみて下さい。 |