

ここでは、noteの「編集部のおすすめ」の記事タイトルをスクレイピングする方法についてサンプルコードを用いて解説しています。
この記事の対象
行ったこと
noteというサイトにおける「編集部のおすすめ」記事のタイトルをスクレイピングしてみました。
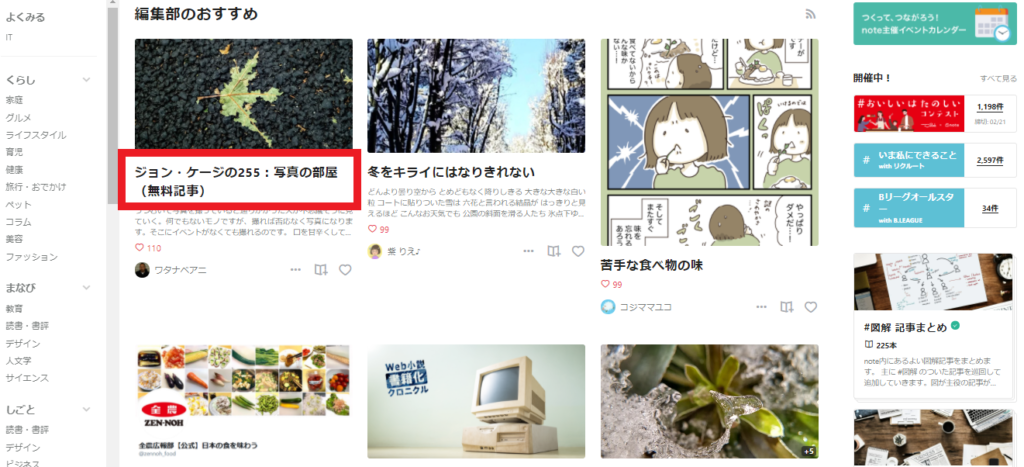
編集部のおすすめの記事のタイトルは「h3」になります。これに該当する文字をスクレイピングしました。
作業手順
- サイト構造の把握
- headers情報の取得
- プログラム作成
いきなりプログラムを作成する前にサイト構造を把握する必要があります。ここではURLが「https://note.com/recommend」でh3の文字を取得します。
次にrequestsでサイトにアクセスするときに必要なheaders情報を把握します。この情報は確認くんで調べることができます。「現在のブラウザー」の情報をメモしておきます。
上記の2つを取得したらプログラムを作成していきます。
プログラム
from bs4 import BeautifulSoup
import requests
#1---URL指定
url = "https://note.com/recommend"
#2---headers指定
headers = {"User-Agent": ""}
soup = BeautifulSoup(requests.get(url, headers = headers).content,'html.parser')
#3---h3のタイトル抽出
all_h3 = soup.select('h3')
for i in range(10):#10抽出
cell = all_h3[i].get_text()
print(cell,">>>",len(cell))
#4---終了の合図
print('*****完了*****')上記がプログラムになります。
それでは解説していきます。
#1---URL指定
url = "https://note.com/recommend"1の部分ではURLを指定しています。
#2---headers指定
headers = {"User-Agent": "*****"}
soup = BeautifulSoup(requests.get(url, headers = headers).content,'html.parser')2の部分ではheadersを指定しています。確認くんなどでブラウザの環境を調べて「*****」を埋めます。次にBeautifulSoupに情報を渡しています。
#3---h3のタイトル抽出
all_h3 = soup.select('h3')
for i in range(10):#10つ抽出
cell = all_h3[i].get_text()
print(cell,">>>",len(cell))3の部分ではh3を探して、for構文で10個出力しています。同時にタイトルの文字数も出力しています。
最後は完了の合図です。
結果

タイトルの抽出と文字数カウントを行いました。
もう少し工夫すれば、色々と解析できそうですね。
スクレイピングしたタイトルをLineに送信してみた
スクレイピングしたタイトルをLine Notifyで送信してみました。良かったら覗いて下さい。
